Proxmox VE
Proxmox VE 9.2: cluster operations grows up
Dynamic CRS load balancing, disarmable HA for safe maintenance windows, WireGuard and BGP SDN fabrics, custom CPU models in the UI, Ceph Tentacle, and a kernel 7.0 baseline.
By Instelligence ·
The 9.x line has moved quickly. 9.0 landed last August on a Debian Trixie base with HA affinity rules and snapshots on shared LVM. 9.1 followed in November with OCI containers, qcow2-backed TPM state, and Intel TDX. 9.2 was released on 21 May 2026, and the focus has shifted. Where the first two releases added new primitives, this one is about making clusters easier to operate at scale, especially for teams running Proxmox in production where downtime windows are short and maintenance has to be coordinated across nodes.
Two changes carry most of the weight. The Cluster Resource Scheduler can now rebalance HA-managed guests on the fly using live utilization data, and the HA stack itself can be safely disarmed cluster-wide for maintenance without triggering fencing. Under those sits a significant expansion of the SDN stack (WireGuard and BGP join OpenFabric and OSPF as fabric protocols), a proper UI for custom CPU models, and a stack refresh that includes Linux kernel 7.0 as the default and Ceph Tentacle as a stable option.
What’s actually new
Dynamic load balancing for HA guests
The Cluster Resource Scheduler used to pick which node a HA-managed guest started on, but it didn’t move guests around in response to changing load. In 9.2, the CRS gains a dynamic mode that uses real-time CPU and memory utilization across nodes and guests to identify imbalance and automatically migrate HA-managed guests to flatten it. Sensitivity and thresholds are tunable from the datacenter options and the HA panel, which matters because a too-aggressive balancer is worse than no balancer at all.

For most clusters this changes the operating model. Instead of capacity-planning around worst-case static placement, you can size to average utilization and let the scheduler handle drift. It also cuts down on manual migration work for bursty workloads and noisy neighbors.
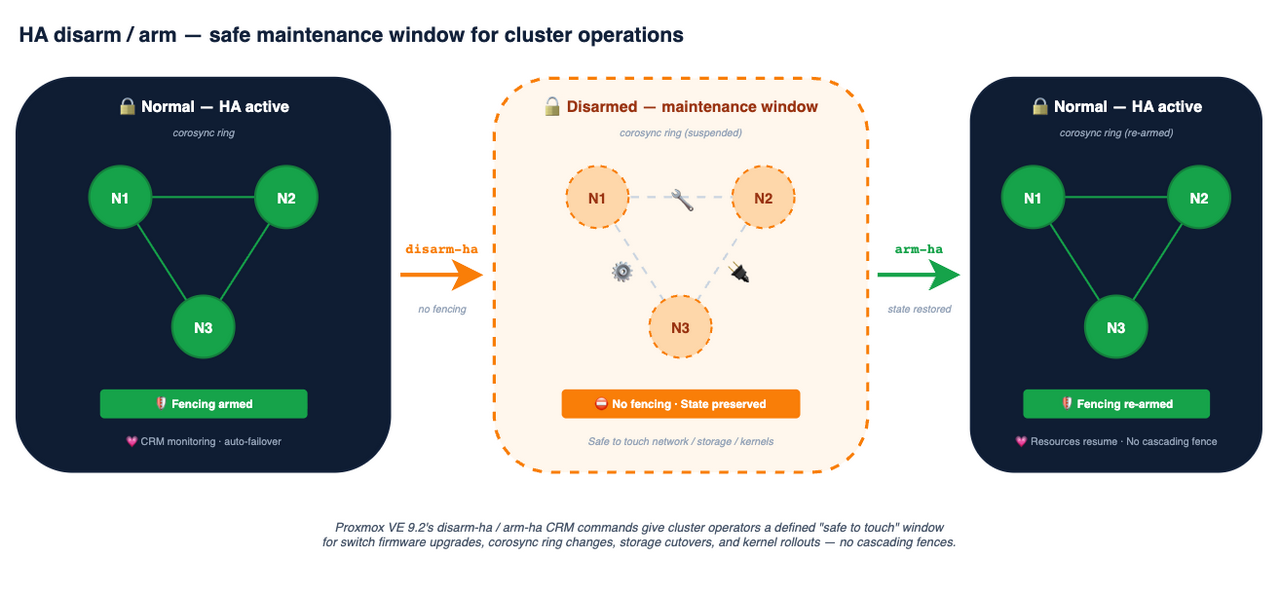
Disarm and arm HA for cluster maintenance
Anyone who has changed cluster network configuration on a live HA cluster knows the special anxiety of watching the corosync ring while you replumb a switch. 9.2 adds disarm-ha and arm-ha CRM commands that suspend the HA stack cluster-wide. Fencing won’t fire during the disarm window, and HA resources go back to their previous state when you arm it again. The resource state is preserved through the window, which is meaningfully different from disabling HA on individual resources and then reconstructing the picture afterward.
This is the kind of change that looks small in a changelog and large in a runbook. Network maintenance, storage cutovers, switch firmware upgrades, kernel rollouts: all of them get a defined “safe to touch” window that doesn’t risk a cascading fence.
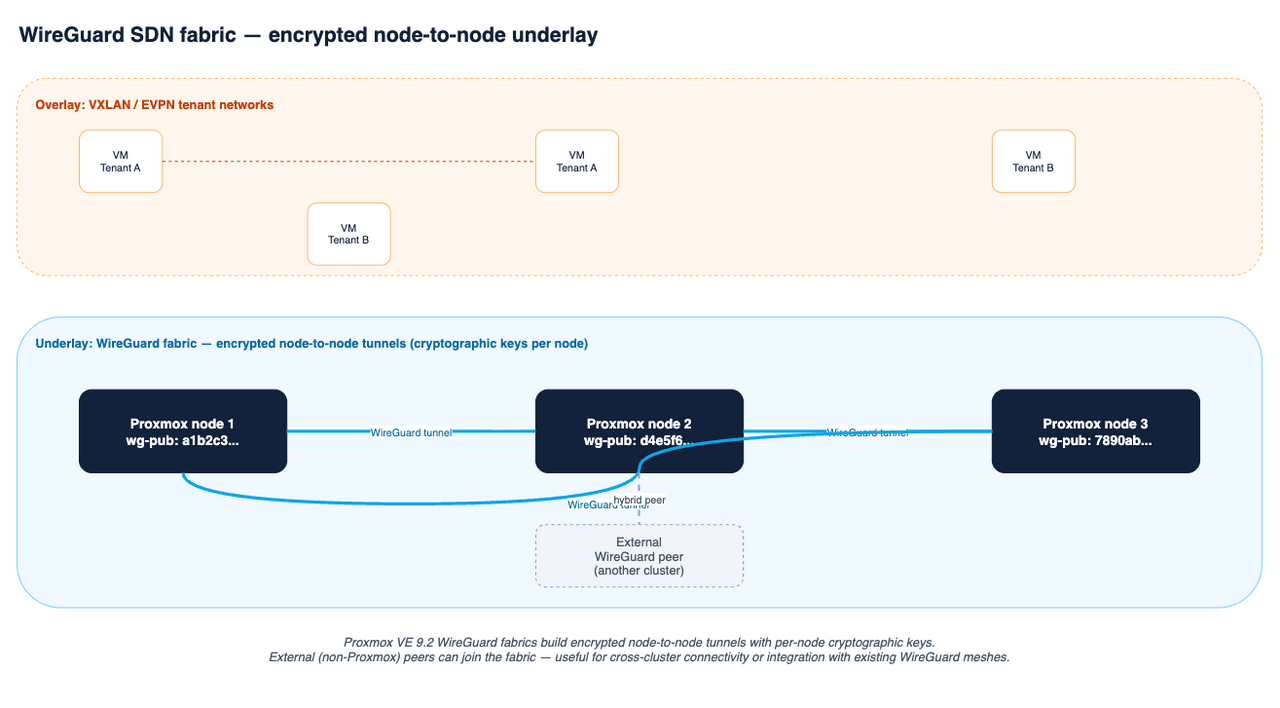
SDN: WireGuard, BGP, route maps, IPv6 EVPN
The SDN stack picked up two new fabric protocols and a useful set of filtering primitives. WireGuard fabrics build encrypted node-to-node tunnels with cryptographic keys generated and managed per node, usable as a secure underlay for VXLAN, migration networks, or cross-cluster connectivity. External (non-Proxmox) WireGuard peers can be added to the fabric too, which opens the door to hybrid topologies where a cluster integrates with existing WireGuard meshes.
BGP fabrics use an eBGP unnumbered underlay where each node is assigned a unique ASN and peers over physical interfaces without requiring IP addresses on the fabric links. That’s the model most large networks already run for spine-leaf, so bringing it into Proxmox SDN means fewer awkward translations between the Proxmox cluster and the network around it.
EVPN gets several improvements at once: multiple EVPN controllers per cluster (which lets you do Inter-AS Option B/C per RFC 4364), per-controller restrictions on which nodes a controller deploys to, IPv6 underlay support, and first-class route maps and prefix lists with their own API endpoints. OSPF fabrics gain route redistribution for multi-protocol setups. SDN configuration changes can also be dry-run before they’re applied, which anyone who has accidentally cut off their own management interface will appreciate.
Custom CPU models in the web UI
Custom CPU models have been a CLI thing for a while. In 9.2 they get a proper management section under Datacenter, and the VM CPU flags selector now indicates which flags each cluster node supports. Cluster-wide compatibility issues surface during VM configuration rather than during a failed live migration. On mixed-generation hardware, that alone removes a class of operational surprise.
Storage, backup, and the smaller wins
A few smaller improvements target friction points that accumulate over time. qcow2 volumes on shared LVM now report approximate sizes without activating each LV, which is useful on Fibre Channel and iSCSI where activating volumes node-by-node is expensive. Snapshots and backups can be triggered from the resource tree context menu. The backup-job guest selector finally has a working search field and a review toggle. iSCSI and ZFS-over-iSCSI now support VMs with TPM state. VMs with VNC clipboard enabled can be live-migrated under QEMU machine version 10.1.
On Ceph, Tentacle (20.2.1) is now the default for fresh installations and available as a stable option on existing clusters. Squid is still supported, and existing clusters aren’t pushed to Tentacle automatically. A handful of Ceph bugs around pool statistics, monitor logging, and the pool edit dialog are also fixed in this release.
Installation and node management
The auto-install assistant can produce PXE- and iPXE-compatible ISOs, supports HTTP authorization tokens for answer file retrieval (for integrating with Proxmox Datacenter Manager), and handles IPv6-only setups correctly. Nodes can also be tagged with a physical location that renders a link to OpenStreetMap, which helps when you’re operating across multiple sites.
What it means in practice
If you run a mid-size cluster with HA workloads, the combination of dynamic CRS balancing and disarm/arm HA is the upgrade case. You spend less time chasing manual migrations, and you stop accumulating risk every time the network team wants to touch a switch.
If you’re an MSP running multi-tenant Proxmox, the SDN additions are the bigger story. WireGuard fabrics for tenant isolation, BGP underlays that align with the rest of your network, route maps for selective tenant route exposure, IPv6-capable EVPN: these are the building blocks for the kind of network topologies that previously required dropping out of Proxmox-managed SDN and configuring FRR by hand.
If you operate clusters with mixed CPU generations, the custom CPU model UI plus per-node flag visibility shortens the workflow for keeping live migration working across the fleet.
If you’re greenfield, the new defaults (kernel 7.0, Ceph Tentacle, QEMU 11) line up the stack you’d want to start on. There’s no urgency to migrate existing Squid clusters to Tentacle. Squid stays supported, and the cluster-version probe pins new nodes to whatever release the cluster already runs.
Where Instelligence comes in
Most of what’s in 9.2 is easy enough to adopt in isolation. The complication is that real environments aren’t isolated. They’re production clusters running tenant workloads, with backup schedules, monitoring integrations, and storage layouts that all need to keep working through an upgrade. Instelligence focuses on the operational side of getting Proxmox environments to a known-good state and keeping them there.
For 9.2 specifically that means upgrade planning that accounts for the kernel 7.0 transition and any driver edge cases on your hardware, a review of HA configuration so you can take advantage of dynamic CRS without catching the team off-guard with unexpected migrations, and SDN architecture work for clusters that want to move to WireGuard or BGP fabrics. For MSPs and multi-tenant operators, MultiPortal extends the Proxmox management surface for multi-tenant scenarios, which lines up well with the new EVPN controller flexibility when per-tenant network isolation matters.
Beyond the upgrade itself, the day-to-day work is deployment automation, monitoring integration, and ongoing operations support. The parts of running Proxmox that don’t change with a point release but get easier with a consistent foundation underneath.
If you’re planning a 9.2 move
The release is stable, the headline features address real operational pain, and the upgrade path from 9.0 or 9.1 is straightforward through APT. Whether to move now depends on your change window, your Ceph version, and whether you have HA workloads that would benefit from dynamic balancing.
If you’re scoping a 9.2 upgrade, or want a read on what these capabilities unlock for your environment, get in touch. We can look at your cluster, identify blockers, and put together a plan that respects your maintenance windows.